
JDBC Nested Set Sink Connector
Demo showcase of JDBC Nested Set Sink Connector for Apache Kafka Connect used to eventually sync hierachical data (e.g. : shop category tree) from Apache Kafka towards a sink database table via Apache Kafka Connect in an untainted fashion without intermittently having corrupt content on the sink database destination nested set model table.
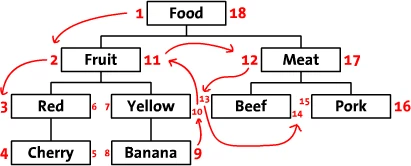
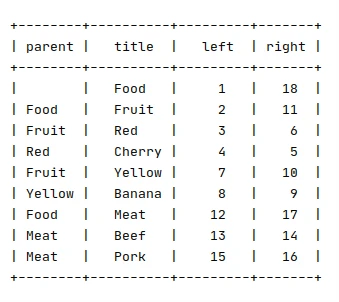
Nested Set Model
There are multiple ways of storing and reading hierarchies in a relational database:
- adjacency list model: each tuple has a parent id pointing to its parent
- nested set model: each tuple has
leftandrightcoordinates corresponding to the preordered representation of the tree
Details about the advantages of the nested set model are already very well described in the following article:
https://www.sitepoint.com/hierarchical-data-database/
TLDR As mentioned on Wikipedia
The nested set model is a technique for representing nested sets (also known as trees or hierarchies) in relational databases.
Syncing nested set models over Apache Kafka
Kafka Connect is an open source component of Apache Kafka which in a nutshell, as described on Confluent blog provides the following functionality for databases:
It enables you to pull data (source) from a database into Kafka, and to push data (sink) from a Kafka topic to a database.
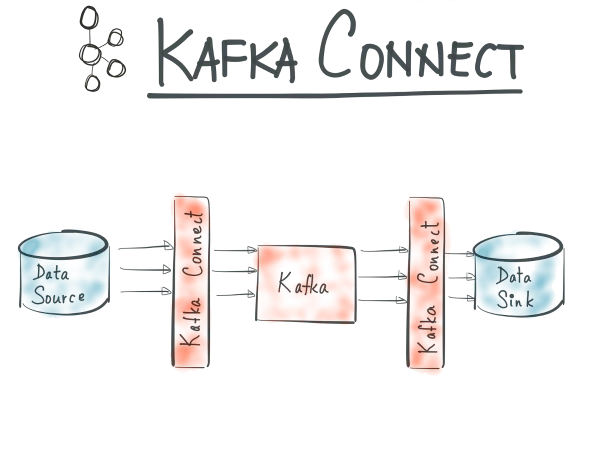
The topic of synchronizing nested set model data between databases has been already discussed in the blog post :
Ever wondered how to sync trees or hierarchies over @apachekafka by making use of @confluentinc kafka-connect-jdbc ? https://t.co/p85iH3a6Yu
— findinpath (@findinpath) April 19, 2020
In the previous blog post the nested set model data published over kafka-connect-jdbc source connector from the source database to Apache Kafka was being handled explicitly in the business logic of the sink microservice application.
It is definitely possible to integrate the synchronization logic for the nested set data explicitly in a microservice that depends on the nested set model data (e.g. : shop category tree), but this adds, possibly unwanted, further complexity to the microservice.
The synchronization functionality for the nested set model data which is a non-core functionality of the microservice needs to be maintained and monitored.
Another possibility would be to delegate the responsibility of syncing the nested set model data to a JDBC Sink Connector from the Confluent Hub. This approach would have the advantage that the microservice consuming the nested set model data would solely concentrate on its core functionality.
This post describes how to use the JDBC Nested Set Sink Connector created to generically sink nested set model data via Apache Kafka Connect in a destination nested set model table.
End to end synchronization over Apache Kafka Connect
Syncing of nested set model from the source database to Apache Kafka
can be easily taken care of by a kafka-connect-jdbc source connector
which can be initialized by posting the following configuration
to the /connectors endpoint of
Kafka Connect (see Kafka Connect REST interface)
{
"name": "findinpath",
"config": {
"connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector",
"mode": "timestamp+incrementing",
"timestamp.column.name": "updated",
"incrementing.column.name": "id",
"topic.prefix": "findinpath.",
"connection.user": "sa",
"connection.password": "p@ssw0rd!source",
"validate.non.null": "false",
"tasks.max": "1",
"name": "findinpath",
"connection.url": "jdbc:postgresql://source:5432/source?loggerLevel=OFF",
"table.whitelist": "nested_set_node"
}
}NOTE in the configuration above, the tasks.max is set to 1 because JDBC source connectors can deal
only with one SELECT statement at a time for retrieving the updates performed on a table.
It is advisable to use also for Apache Kafka a topic with only 1 partition for syncing the nested set content
towards downstream services.
Syncing of the nested set model data from Apache Kafka towards the sink database can be now easily taken care of by the JDBC Nested Set Sink Connector:
{
"name": "jdbc-nested-set-node-sink",
"config": {
"name": "jdbc-nested-set-node-sink",
"connector.class": "com.findinpath.connect.nestedset.jdbc.NestedSetJdbcSinkConnector",
"tasks.max": "1",
"topics": "findinpath.nested_set_node",
"connection.url": "jdbc:postgresql://sink:5432/postgres",
"connection.user": "sa",
"connection.password": "p@ssw0rd!sink",
"pk.fields": "id",
"table.name": "nested_set_node",
"table.left.column.name": "lft",
"table.rgt.column.name": "rgt",
"log.table.name": "nested_set_node_log",
"log.table.primary.key.column.name": "log_id",
"log.table.operation.type.column.name": "operation_type",
"log.offset.table.name": "nested_set_node_log_offset",
"log.offset.table.log.table.column.name": "log_table_name",
"log.offset.table.offset.column.name": "log_table_offset"
}
}Functionality overview
The JDBC Nested Set Sink Connector is relatively similar in functionality to the JDBC Sink Connector for Confluent Platform because it ingests SinkRecord entries and writes them in a database table. This is also the reason why this connector made use of a great part of the sink logic of the kafka-connect-jdbc project code.
The JDBC Nested Set Sink Connector writes the sink records in a database table structure similar to the one shown below:
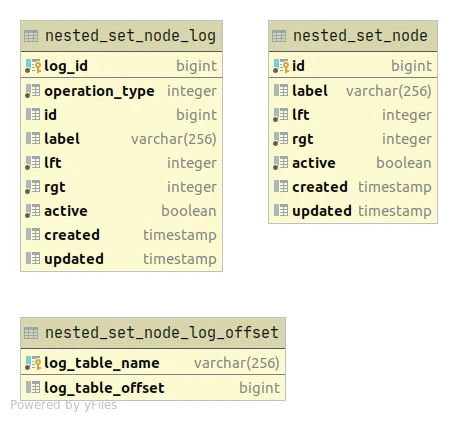
The nested_set_node_log table is an INSERT only table which simulates a certain extent the transaction logs on the nested set model data.
After writing new entries on the nested_set_node_log table, there will be an attempt to synchronize them towards the destination nested_set_node table. This operation will succeed only when the nested set model resulting from the merge of:
- existing content from the nested_set_node table
- new nested_set_node_log table entries
is valid.
The table nested_set_node_log_offset will contain only a pointer towards the ID of the latest nested_set_node_log entry synchronized successfully into the nested_set_node table.
NOTE: The microservice that makes use of the nested set model tree content should continuously poll the table nested_set_node_log_offset in order to know when the nested set model has been updated.
At the time of this writing the connector supports and has been tested with the following databases:
- Postgres 12
- MySQL 8
- MS SQL Server 2017
- sqlite 3
- Oracle 18.4.0 XE
The JDBC Nested Set Sink Connector supports both:
- upsert: the position of the node in the tree or its data can be upserted (updated/inserted)
- deletion: the node can be removed from the tree (works with Debezium change data capture Kafka Connect source connector)
operations on the nested set model entries.
Testing
It is relatively easy to think about a solution for the previously exposed problem, but before putting it to a production environment the solution needs proper testing in conditions similar to the environment in which it will run.
This is where the testcontainers library helps a great deal by providing lightweight, throwaway instances of common databases that can run in a Docker container.
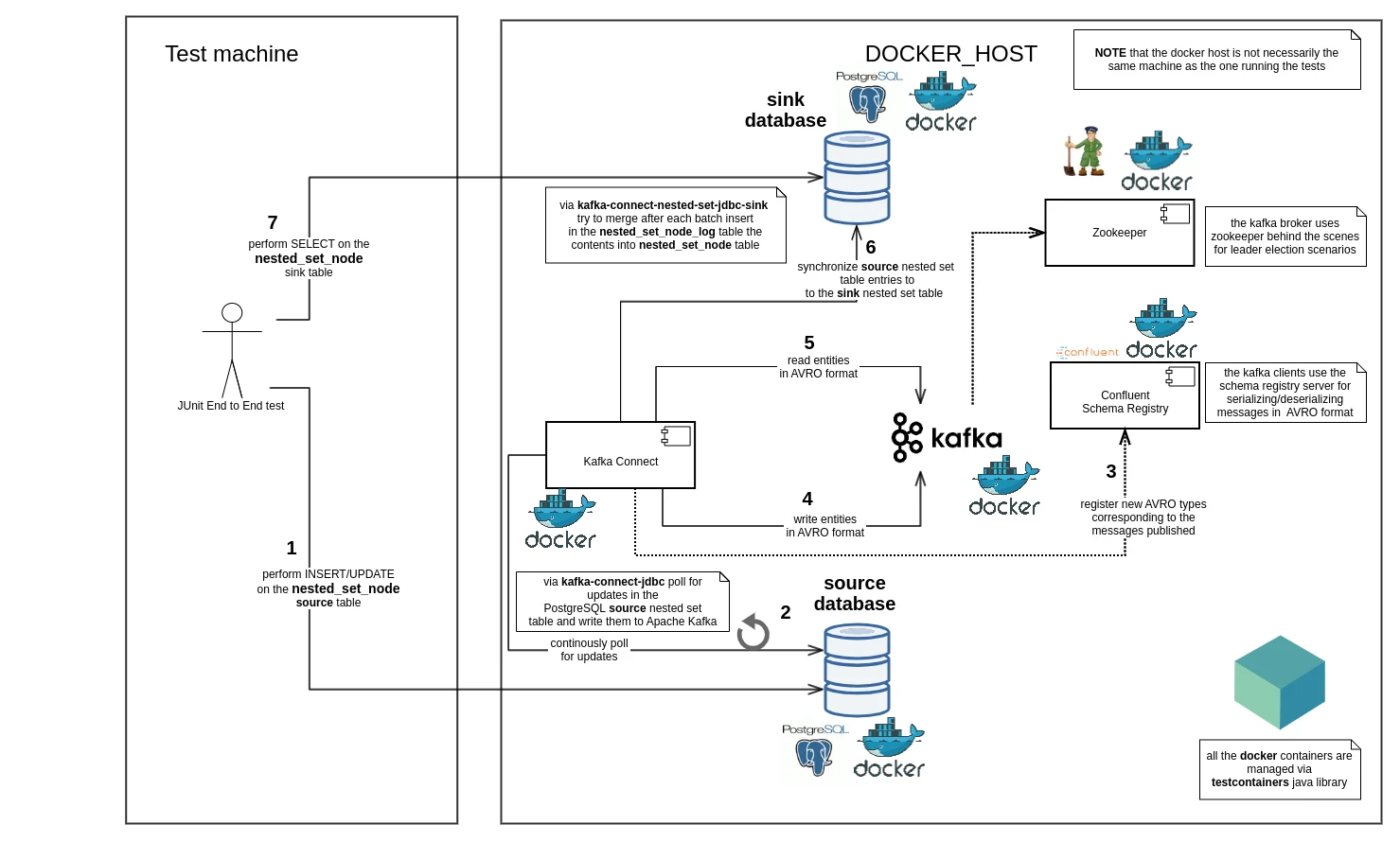
Docker containers are used for interacting with the Apache Kafka ecosystem as well as the source and sink databases.
This leads to tests that are easy to read and allow the testing of the sync operation for various nested set models
/**
* Ensure that the sync the content of a more complex nested set model
* is performed successively each time after performing updates on the
* nested set model on the source database.
*/
@Test
public void syncingSuccessiveChangesToTheTreeDemo() {
long clothingNodeId = sourceNestedSetService.insertRootNode("Clothing");
awaitForTheSyncOfTheNode(clothingNodeId);
logSinkTreeContent();
// The current structure of the tree should be:
// |1| Clothing |2|
// Add now Men's and Women's children and wait for the syncing
long mensNodeId = sourceNestedSetService.insertNode("Men's", clothingNodeId);
long womensNodeId = sourceNestedSetService.insertNode("Women's", clothingNodeId);
awaitForTheSyncOfTheNode(womensNodeId);
logSinkTreeContent();
// The current structure of the tree should be:
// |1| Clothing |6|
// ├── |2| Men's |3|
// └── |4| Women's |5|
// Add new children categories for both Men's and Women's nodes
sourceNestedSetService.insertNode("Suits", mensNodeId);
sourceNestedSetService.insertNode("Dresses", womensNodeId);
sourceNestedSetService.insertNode("Skirts", womensNodeId);
sourceNestedSetService.insertNode("Blouses", womensNodeId);
awaitForTheSyncOfTheNode(womensNodeId);
logSinkTreeContent();
// The current structure of the tree should be:
// |1| Clothing |14|
// ├── |2| Men's |5|
// │ └── |3| Suits |4|
// └── |6| Women's |13|
// ├── |7| Dresses |8|
// ├── |9| Skirts |10|
// └── |11| Blouses |12|
}See DemoNestedSetSyncTest for several syncing test cases.
This project provides a functional prototype on how to setup the whole Confluent environment (including Confluent Schema Registry and Apache Kafka Connect) via testcontainers.
See AbstractNestedSetSyncTest for details.
Source code
Checkout the github project kafka-connect-nested-set-jdbc-sink.
Try out the tests via
mvn clean testInstallation notes
The connector is available on Confluent Hub and can be installed via the following command:
confluent-hub install findinpath/kafka-connect-nested-set-jdbc-sink:1.0.0